

Published
NOTE: This is a preview. All Kafka Summit videos available in full at https://confluent.io/kssf17 | You have made the transition from single machines and one-off solutions to distributed infrastructure in your data center powered by Apache Kafka. But what if one data center is not enough? In this session, we review resilient data pipelines with Apache Kafka that span multiple data centers. We provide an overview of best practices and common patterns including key areas such as architecture and data replication as well as disaster scenarios and failure handling.
CONNECT
Subscribe: http://youtube.com/c/confluent?sub_confirmation=1
Site: http://confluent.io
GitHub: https://github.com/confluentinc
Facebook: https://facebook.com/confluentinc
Twitter: https://twitter.com/confluentinc
Linkedin: https://www.linkedin.com/company/confluent
ABOUT CONFLUENT
Confluent, founded by the creators of Apache™ Kafka™, enables organizations to harness business value of live data. The Confluent Platform manages the barrage of stream data and makes it available throughout an organization. It provides various industries, from retail, logistics and manufacturing, to financial services and online social networking, a scalable, unified, real-time data pipeline that enables applications ranging from large volume data integration to big data analysis with Hadoop to real-time stream processing. To learn more, please visit http://confluent.io
CONNECT
Subscribe: http://youtube.com/c/confluent?sub_confirmation=1
Site: http://confluent.io
GitHub: https://github.com/confluentinc
Facebook: https://facebook.com/confluentinc
Twitter: https://twitter.com/confluentinc
Linkedin: https://www.linkedin.com/company/confluent
ABOUT CONFLUENT
Confluent, founded by the creators of Apache™ Kafka™, enables organizations to harness business value of live data. The Confluent Platform manages the barrage of stream data and makes it available throughout an organization. It provides various industries, from retail, logistics and manufacturing, to financial services and online social networking, a scalable, unified, real-time data pipeline that enables applications ranging from large volume data integration to big data analysis with Hadoop to real-time stream processing. To learn more, please visit http://confluent.io
- Category
- Data Centers
Be the first to comment
Up Next
Autoplay
-
2:15:10

Google Efficient Data Centers Summit - 2 of 3
-
58:22
AWS re:Invent 2017: Extending Data Centers to the Cloud: Connectivity Options and Co (NET301)
-
1:05:39
Scaling the Cloud: Hyper Evolution of Data Centers
-
05:48
Scale Your Cloud over Multiple Data Centers with Juniper Contrail
-
44:41
Building Large Scale Stream Infrastructures Across Multiple Data Centers with Apache Kafka
-
49:05
Google Efficient Data Centers Summit - 3 of 3
-
31:14
OCP 2020 Virtual Summit: SONiC: Multi-Tenant Data Centers with EVPN VXLAN
-
00:34
Oak Ridge National Summit Supercomputer Preview at SC '17
-
06:13
Dynamically scale apps between data centers and public cloud | Azure Stack hybrid scaling
-
02:24
Case Study: Tromso Uses Cisco ACI to Expand Data Centers in Multiple Locations
-
01:59

QSFP28 100G Optical Transceivers in the New Data Center
-
25:20

How much is a 100G QSFP28 transceiver?
-
02:50

How about the feature of QSFP28 QSFP+ SFP+ XFP CWDM DWDM BIDI module? (LD, PD, Tx Power, Rx Sens )
-
02:21

Finisar Demonstrates 100G QSFP28 ER4f Transceiver at ECOC 2017
-
02:12

QSFP28 100G testing between Arista and Huawei
-
01:59
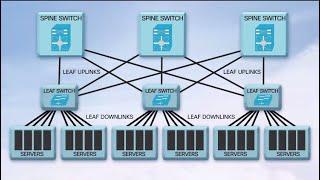
QSFP28 100G Transceivers in the New Data Center
-
04:34

Unboxing and Replace QSFP Broken || JNP QSFP 100G SR4 || SFP Module || Juniper
-
08:25
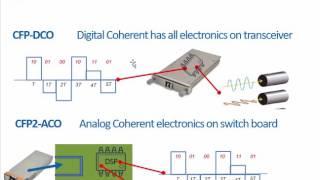
100G Transceivers Development
-
02:07

QSFP28 100G Transceivers: Key Features and Applications
-
04:09

Finisar QSFP28 Family Transceiver Demonstration at OFC 2015

